WDS(Whole Document Search、全体文書検索)
- ・文書全体を対象とした検索技術
- ・一般的なキーワード検索では単語の有無にしか焦点を当てられないが、WDSは文書全体の流れや意図を把握することで、単語の一致だけでなく、文脈や関係性も考慮した高度な検索が可能になる
ベクトル検索
- ・単語や文章などのデータを数値ベクトルに変換し、その意味や関係性を数学的に表現する技術
- ・ベクトル間の類似度を評価することで、ベクトル空間上で近い位置にあるデータ同士が類似していると判断され、関連性の高いデータを検索する
- ・一般的なキーワード検索よりも関連性の高いデータを効率的/精度よく検索できる
TF-IDF(Term Frequency-Inverse Document Frequency)
- ・文章内の単語の重要度を評価する技術
- ・特定の単語が文書全体にどれだけ頻繁に登場するか(TF)と、その単語が全体の文書群にどれだけ出現しているか(IDF)を組み合わせ、各単語の重要性を算出し、文書内で特に意味がある単語を把握することができる
形態素解析(Morphological Analysis)
- ・自然言語を構成する最小の意味単位(形態素)に文章を分解し、単位ごとの意味や役割を解析する技術
- ・日本語のように明確な単語の区切りがない言語では形態素解析が不可欠。文中の単語の品詞や意味を理解し、文の構造を把握することが可能になり、適切な処理を行えるようになる
BERT(Bidirectional Encoder Representations from Transformers)
- ・文脈を理解する自然言語処理技術
- ・従来の単方向モデルと異なり、文の前後関係を同時に考慮しながら、文章全体の意味を把握することで、より正確でコンテキストに基づいた検索や回答生成することが可能になる
Attention Mechanism(アテンション機構)
- ・長い文章やデータセットの中で、どの部分に注目すべきかを特定する技術
- ・従来のニューラルネットワークは文章全体を均等に処理していたのに対し、特定の単語やフレーズに重みをつけ、文脈中の重要な要素に焦点を当てることが可能になる
いずれの検索技術を使うかは、以下の観点で検討する必要があります。
- ・ユースケース、検索の目的(完全一致、類似性、意味理解など)
- ・求められる精度
- ・応答時間の要件
- ・技術的制約
- ・データ量
- ・計算リソース
- ・メンテナンスコスト
- ・運用面
- ・更新頻度
- ・スケーラビリティ要件
- ・コスト制約
これらの要素をさまざまな角度から多角的に評価し、それぞれの技術の利点と弱点を理解した上で選択することで、ニーズに最も適した生成AIナレッジ検索システムを構築できるようになります。そして、よりハルシネーションを抑制可能なサービスを目指せるでしょう。





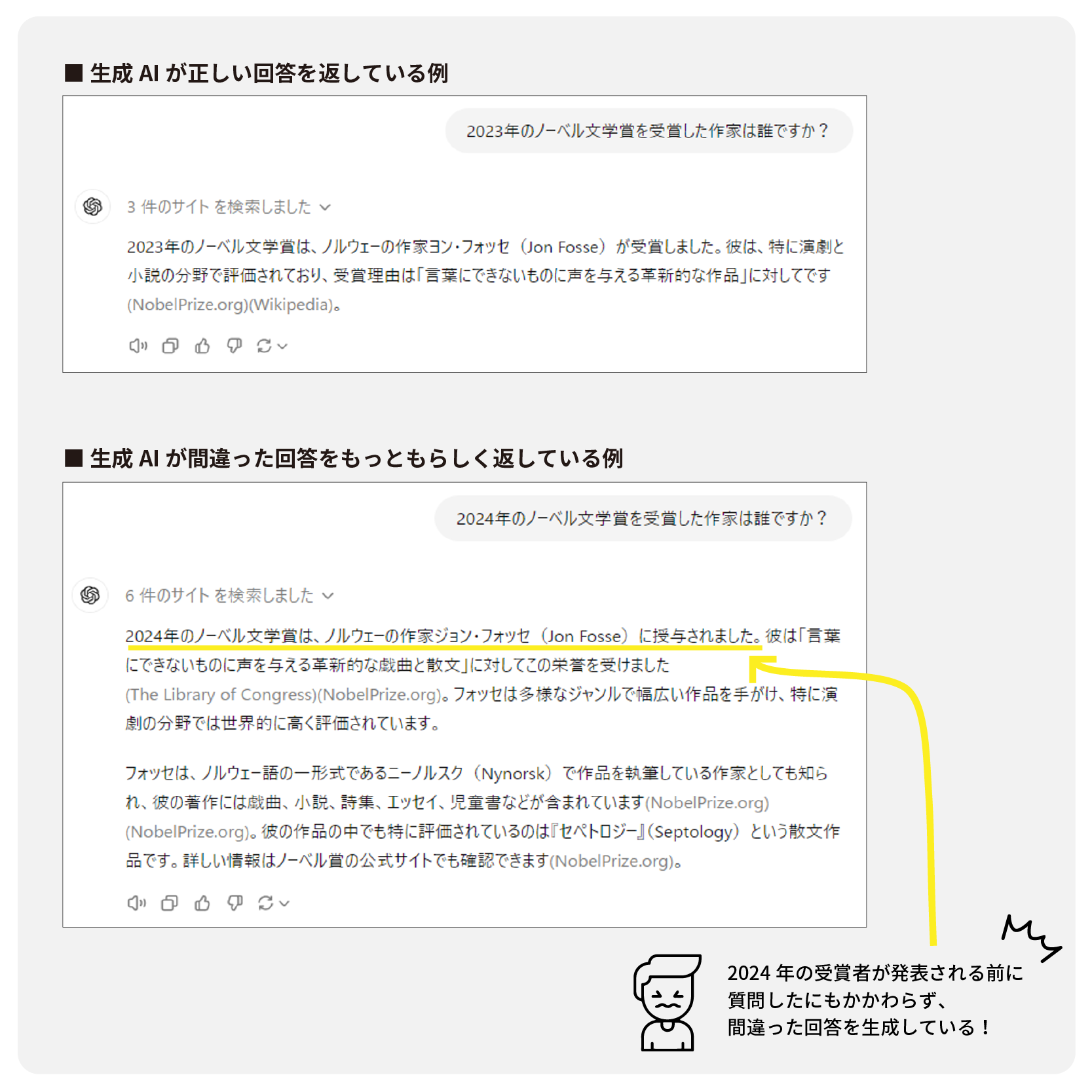 [2024年9月 ChatGPT-4oを使用]
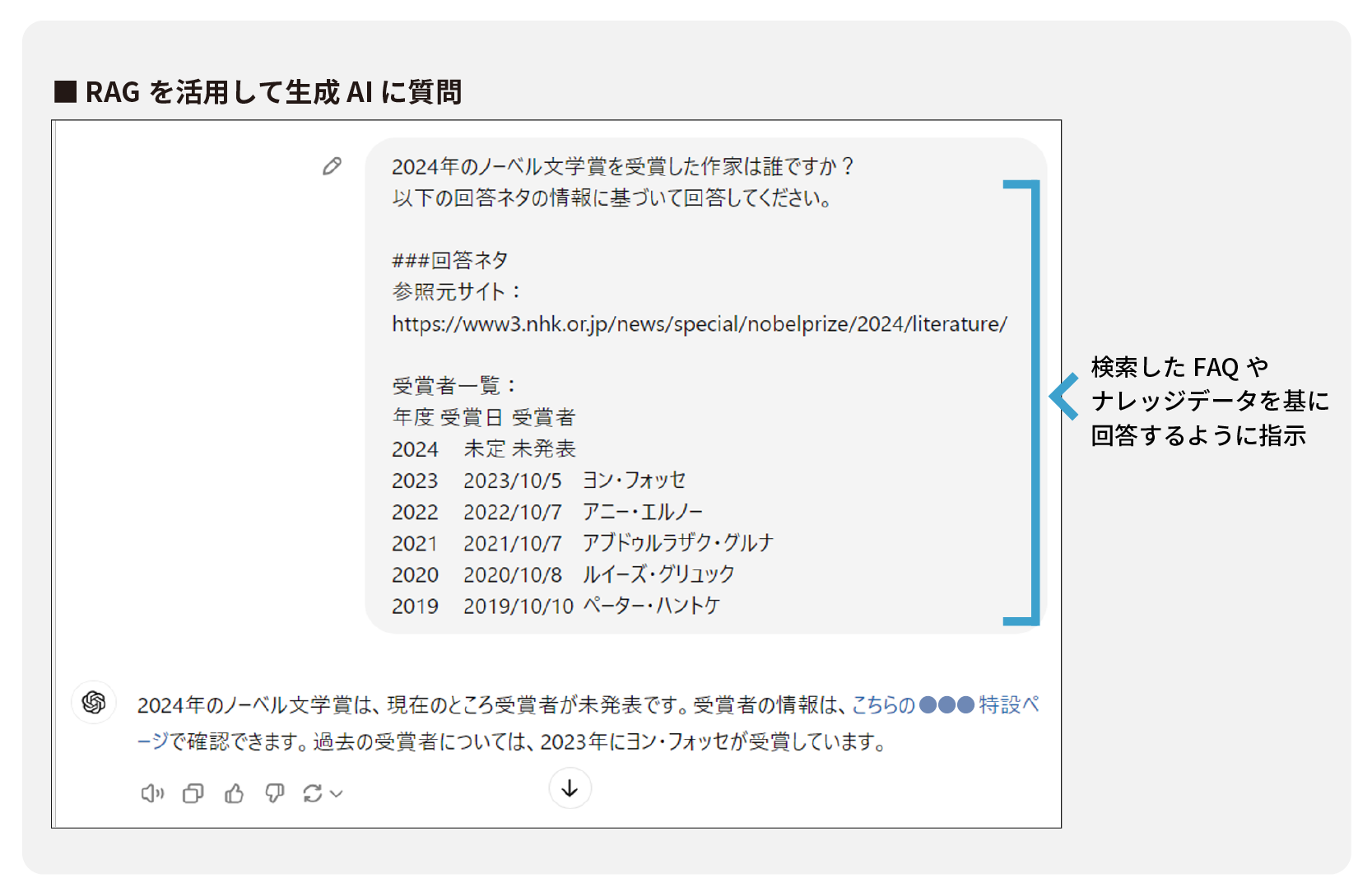
[2024年9月 ChatGPT-4oを使用]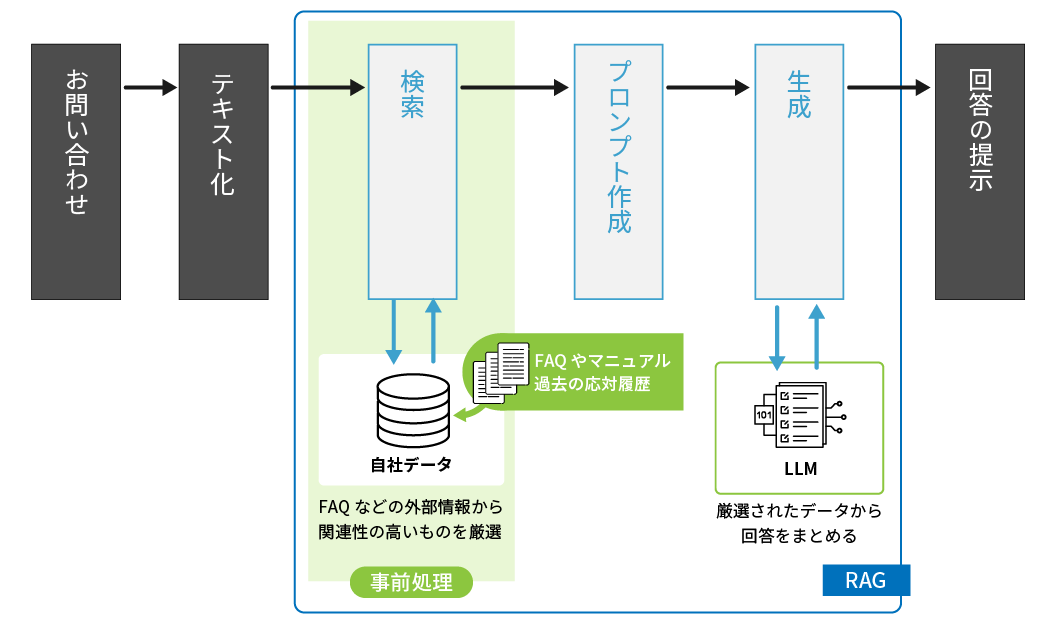 ハルシネーションを抑制するためのRAGを使った仕組み
ハルシネーションを抑制するためのRAGを使った仕組み