シンクラ概論の5回目でハイブリッドストレージとオールフラッシュストレージの活用において、オールフラッシュストレージをVDIで採用するのは現実的でないとの見解を述べた。しかし、2014年末に実施した、あるオールフラッシュストレージの評価検証が、その考えを180度転換させた。
今回は、シンクラ概論『番外編』として、オールフラッシュストレージであるPure Storage社のFlashArrayとVMware社のHorizon Viewとの組み合わせの検証結果を交えながら、今後のVDIにおけるオールフラッシュストレージの活用方法を紹介しよう。
オールフラッシュストレージの問題点
従来のストレージでは磁気記憶媒体にHDDを利用するのに対し、オールフラッシュストレージはすべてSSDなどのフラッシュデバイスで構成される。HDD単体あたりのIOPSは数十から数百であるが、フラッシュデバイスでは1万を超えてくるため、当然、HDDで構成する従来ストレージよりもオールフラッシュストレージの方が圧倒的にパフォーマンスは高い。
しかし、そんなオールフラッシュストレージにも課題はある。それは価格が高い点と、フラッシュデバイスへの書き込み制限である。
フラッシュデバイスの価格は年々下がってきており、HDDとの価格差は以前よりも少なくなってきている。しかし、それでもSAS(10,000回転)に対しては3~5倍程度、SATAに至っては20倍程度割高である。
また、現在フラッシュデバイスの多くはNAND型フラッシュと言われるものであり、HDDとは異なり、書き換え可能回数に上限があるため、故障しなくても寿命がきた時点で交換が必要となる。これは、メーカー保守の高価格化や制限などの問題を引き起こしている。
Pure Storage社のFlashArrayとは?
オールフラッシュのメリット・デメリットを踏まえた上で、今回評価検証を行ったPure Storage社のFlashArrayを紹介しよう。
FlashArrayは、記憶磁気媒体すべてにSSDを搭載したオールフラッシュストレージだ。オールフラッシュストレージの中には、フラッシュデバイスがホットスワップに対応していなかったり、ストレージコントローラが完全な冗長構成になっていない製品も珍しくないのだが、FlashArrayは、これらの部分はもちろん網羅されている。さらに、データ保護のためのSnapShotやレプリケーション機能も標準で搭載しているのだ。
しかし、FlashArrayを語る上で欠かせないのは、『インライン重複排除プラス圧縮機能』と『RAID-3D』と呼ばれるFlashに最適化されたPure Storage社独自のRAIDテクノロジーである。
FlashArrayのインライン重複排除と圧縮機能
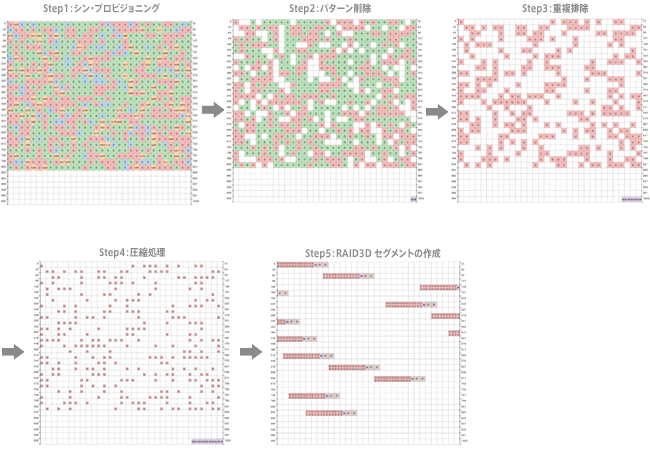
ストレージ内に重複しているデータが存在する場合、同一のデータをポインター参照させ、保存するのは単一データのみにすることで、ストレージの容量削減やストレージキャッシュの効率化によるパフォーマ向上をもたらす重複排除機能は、最近のストレージでは一般的な機能だ。ハイブリッドストレージやオールフラッシュストレージの場合、フラッシュデバイスの利用効率化や書き込み回数の抑止のためにデバイスに書き込む前に重複排除してしまうインライン重複排除という機能を搭載しているケースもある。
では、FlashArrayのインライン重複排除は、他のストレージと何が違うのか?
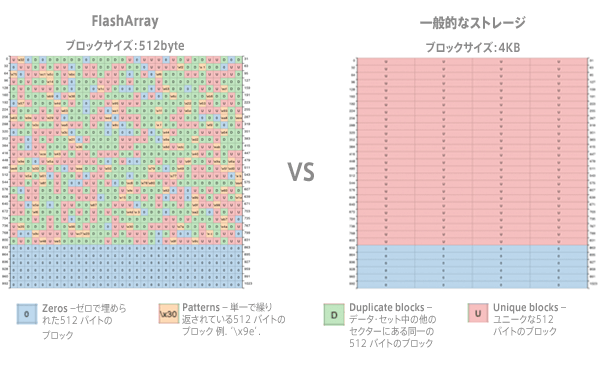
一般的なストレージの重複排除は、4KBのブロックサイズを軸に重複排除を行うが、FlashArrayでは512Bのブロックサイズで重複排除を実施する。
FlashArraynインライン重複排除を見てみよう。
当然、粒度を細かくすれば重複排除の対象となる同一データは増えるため削減率は向上するが、FlashArrayでは、さらに重複排除後のデータを圧縮し、極限までストレージ書き込むデータを小さくしているため、一層のパフォーマンス向上が期待できるのだ。
RAID-3D
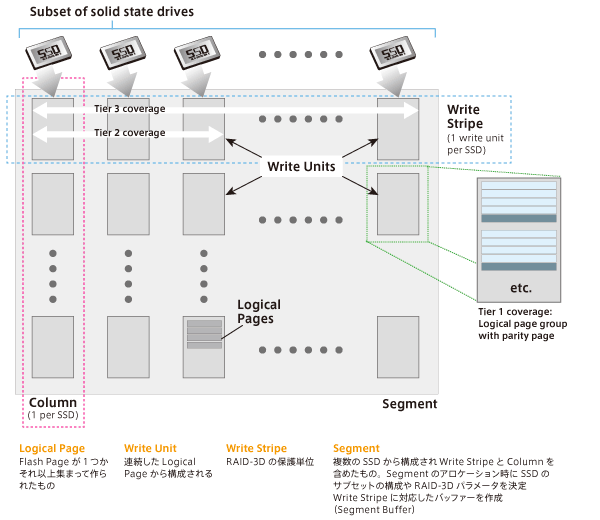
RAID5やRAID6などのRAID方式は、HDDの利用を前提としたものであり、それをそのままフラッシュデバイスに適用したとしてもフラッシュの性能を100%活かしきれない。Pure Storage社では、「RAID-3D」という、フラッシュを最適化するために再設計した独自のRAID方式を採用している。RAID-3Dでは、1つ以上のFlash PageをLogical Pageとして扱い、連続したLogical PageをWrite Unitという単位で管理している。さらに、SSDごとのWrite Unitを束ねたものをWrite Stripeとして扱う。Write UnitやWrite Stripeは各単位でパリティを有しており、3階層からなるデータ保護方式をとっている。
第一階層では、Write Unit内の単一のページエラーをロジカルページ内のチェックサムと分散パリティページから修正し、第二階層ではWrite Stripe内の単一Write UnitエラーではWrite Unitのサブセット単位で作成されているRAID5相当のパリティから復旧する。それでも復旧できない場合には、第三階層としてWrite Stripe全体で保持しているRAID6相当のパリティから復旧する。
RAID-3Dでは、データ保護単位は、ドライブ単位ではなくWrite Unitと、保護単位の粒度が細かいため、Failしたドライブのリビルド時間の短縮やドライブ追加やリプレース時のデータレイアウトの変更が必要ない。また、HDDベースのRAIDのように専用のスペアディスクは必要なく、全体でスペアを構成するようなデータ配置となっている。
検証項目
では、実際にS&IがPure Storages社のFlashArrayに対して行った検証について紹介しよう。
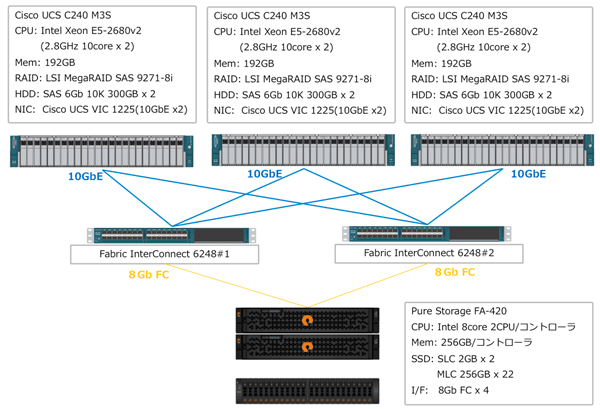
まず、検証環境に、サーバにはCisco UCS C240 M3を3台、ストレージにはPure Storage FlashArrayのミッドレンジモデルであるFA-420、VDI環境にはVMware社のHrizon 6を採用し、仮想デスクトップOSにはWindows 7を展開している。
検証1:IOベンチ測定
検証結果についてIOベンチの結果から見ていこう。
S&Iでは、FlashArray以外の製品についても、数社の製品でIOベンチの測定を実施している。その結果と比較してみよう。
まず、シーケンシャルアクセスだが、他社の製品は、Read100~150MB/s、Write50~100MB/sで推移している。一方で、FlashArrayは、Read589MB/s、Write242MB/sとなっている。また、仮想環境上のIO性質であるランダムアクセスでも他社製品はReadで60MB/s~160MB/s、Writeで40MB/s~80MB/s程度であるのに対してFlashArrayでは、Read545MB/s、Write218MB/sと、比較にならないほど高い数値を示していることがわかる。
他社製品にはSSDを利用したHybrid Storageもあるため、単純にSSDとHDDの性能差だけはないことがわかる。
検証2:クローン時間測定
次に、クローン時間の結果、「vSphere上に存在する実行容量10GB、50GB、100GBの仮想マシンをvCenterから仮想マシンのクローン機能を利用して完了までにかかった時間」を計測した結果を見てみよう。
クローン時間も、他社の製品に比べ、FlashArrayはすべて高い数値を記録している。今回は、ソースの仮想マシンの保存先をESXiのローカルストレージにしているが、ソースもそれぞれのストレージ上にした場合、時間差はもっと拡大する。
※今回は、純粋なクローン時間測定を目的としているため、VAAIは利用していない。
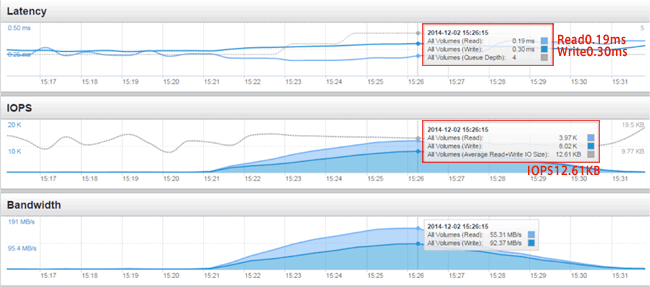
検証3:200VD一斉ログオン
あるVDI環境に対する負荷シミュレーションツールを利用して、200ユーザが一斉にHorizon View環境にログインした際のストレージの負荷状況を検証してみよう。
特に、ストレージの遅延状況に注目すると、本検証で発生する最も高いIOPSは10,000程度になるが、その時点での遅延時間を見てみると、他社製品では数ms、多いのものでは数十msになるが、FlashArrayでは、Read/Write共に常時0.5ms以下を記録している。まだまだ性能に余裕があることがわかる。
検証4:リンククローン1,000VD展開
最後に、Horizon 6のView Composerの機能を利用したリンククローンデスクトップ1,000台の展開検証だが、こちらは展開時間とFlashArrayのディスク使用量の2つの面で見ていきたい。
まず展開時間だ。ご存じの方も多いと思うが、ViewComposerを利用したリンククローンの展開は仮想デスクトップの実態はコピーしないため、フルクローンに比べて展開速度は速い。しかし、それでも従来ストレージでは1,000台展開するのに5時間前後は要する場合が多い。ではFlashArrayではどうかと言うと、1,000台の展開にかかった時間は、わずか1時間43分である。
ViewComposerによるリンククローンの課題は肥大化したデルタディスクのメンテナンスであるRefresh作業と新しいマスターイメージの再展開であるRecomposeをどのタイミングで実施するかであったが、この時間であれば、日次でも夜中に実施することも現実的である。
次に、使用ディスク使用量を確認しよう。今回展開したWindows 7は、HDDが40GB/メモリ1GBなので、実際にフルクローンした場合には、40GB×1,000+1GB(vSwap分)×1,000=41,000GBが必要となる。また、実体をコピーしないリンククローンでvSphere上のディスク使用量を確認したところ、展開直後の状態で約2TB消費されていた。この内訳は、展開後の差分領域と仮想デスクトップごとに配置される1GBのvSwapファイルの容量となる。
それに対して、Pure Storageの使用量は、わずか82GBしか消費されていなかった。当然初期展開時点であるため、利用していけばデータ削減率は低くなっていくと思われるが、VDI環境では非常に少ない搭載容量で多くの仮想デスクトップを収容できることがわかる。※参考までに1,000台展開時の最大IOPSは43,000を記録しているが、その時の遅延はReadで0.3ms、Writeでも1.06msであった。
検証から見えてきたVDI環境におけるオールフレッシュストレージの可能性
今回の検証結果をまとめると、VDIとオールフラッシュストレージの組み合わせは、HDDストレージやハイブリッドストレージに対して仮想デスクトップに大幅なIOパフォーマンスを提供する。
従来のVDIのストレージサイジングでは、仮想マシンあたり10~20程度のIOPSでサイジングすることが多く、ファットクライアントに対してかなり低パフォーマンスな場合が多かった。そのため、IO負荷が一斉にかかる朝一のログオンやウイルススキャン、定義ファイルのアップデートなどは時間をずらすなど運用面で回避するのが一般的であった。しかし、オールフラッシュストレージでは、仮想デスクトップあたり100IOPSを超えるパフォーマンスを提供できるため、乱暴な言い方をすれば、負荷をさほど気にしなくても良いという事になる。
オールフラッシュの最大の課題はコストである。しかし、Pure Storage社のFlashArrayでは粒度の細かいインライン重複排除とインライン圧縮により、VDI環境では大幅なディスク使用量の削減を実現することで、イニシャルコストをHDD単価と同等水準まで抑え、SSDへの書き込み量を極限まで低下させることでSSDに対しても長期間の保守を提供している。そのため、VDIとPure Storage社のFlashArrayの組み合わせはコストはHDDやハイブリッドストレージと同等で、数百倍のパフォーマンスを持つ環境を実現することができる。以前は、VDIへのオールフラッシュの適用が一般的になるのは個人的には1~2年程度先かと考えていたが、Pure Storage社のFlashArrayとの遭遇は、その期間をぐっと縮めるきっかけとなり、非常に魅力的なストレージであると考える。