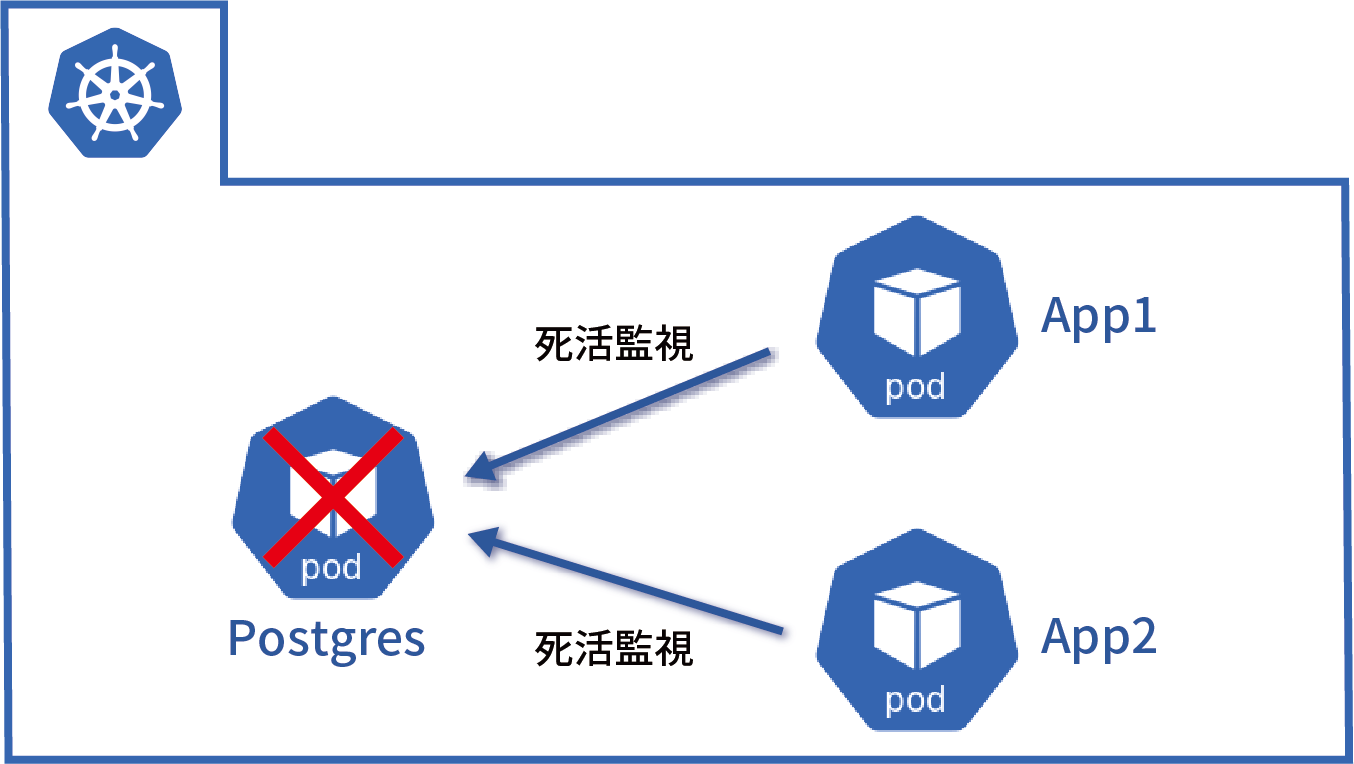
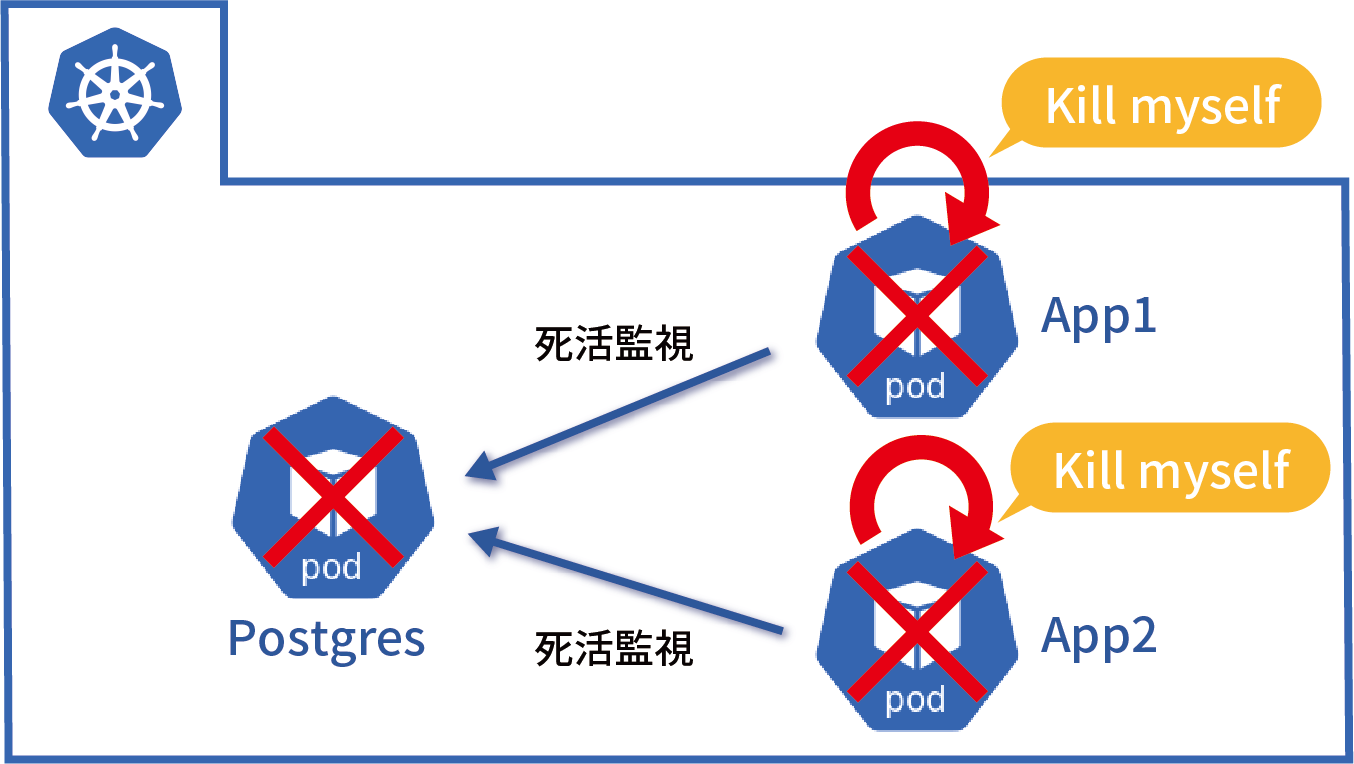
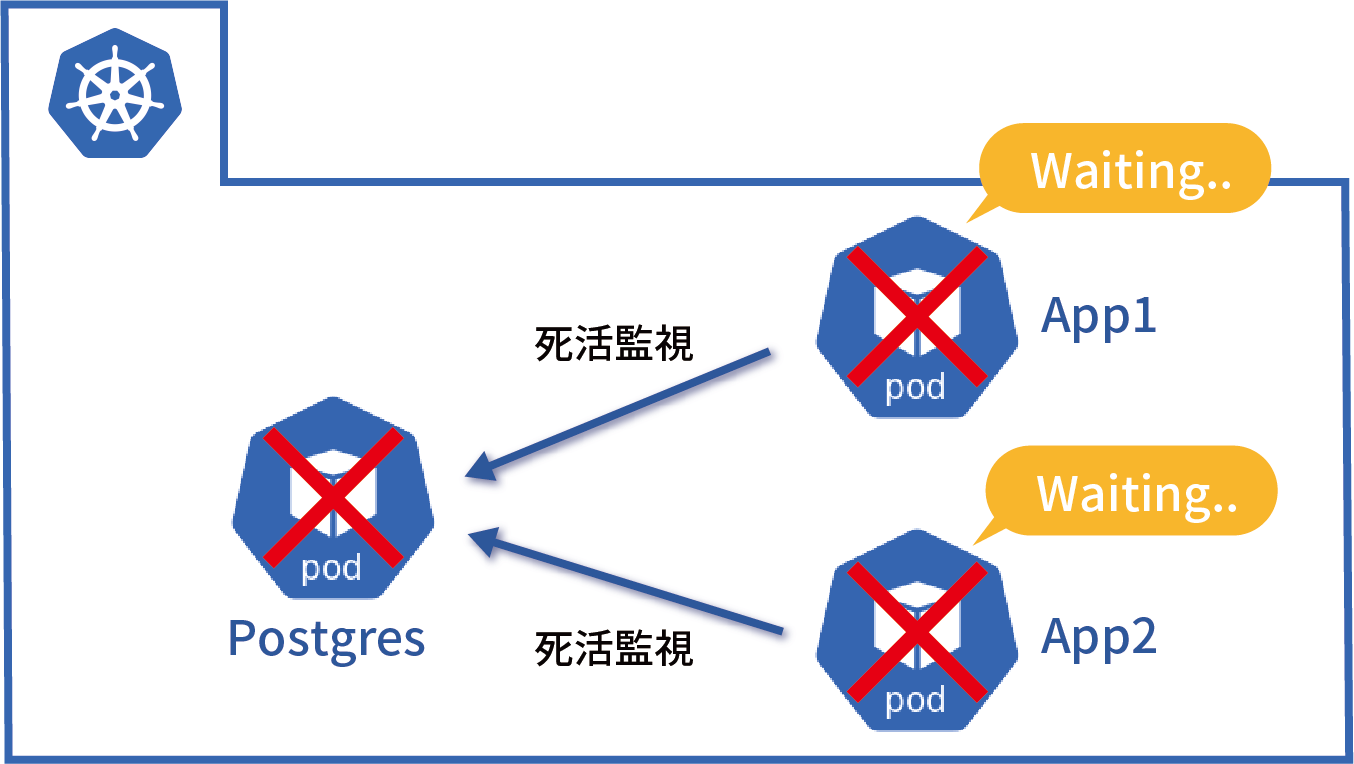
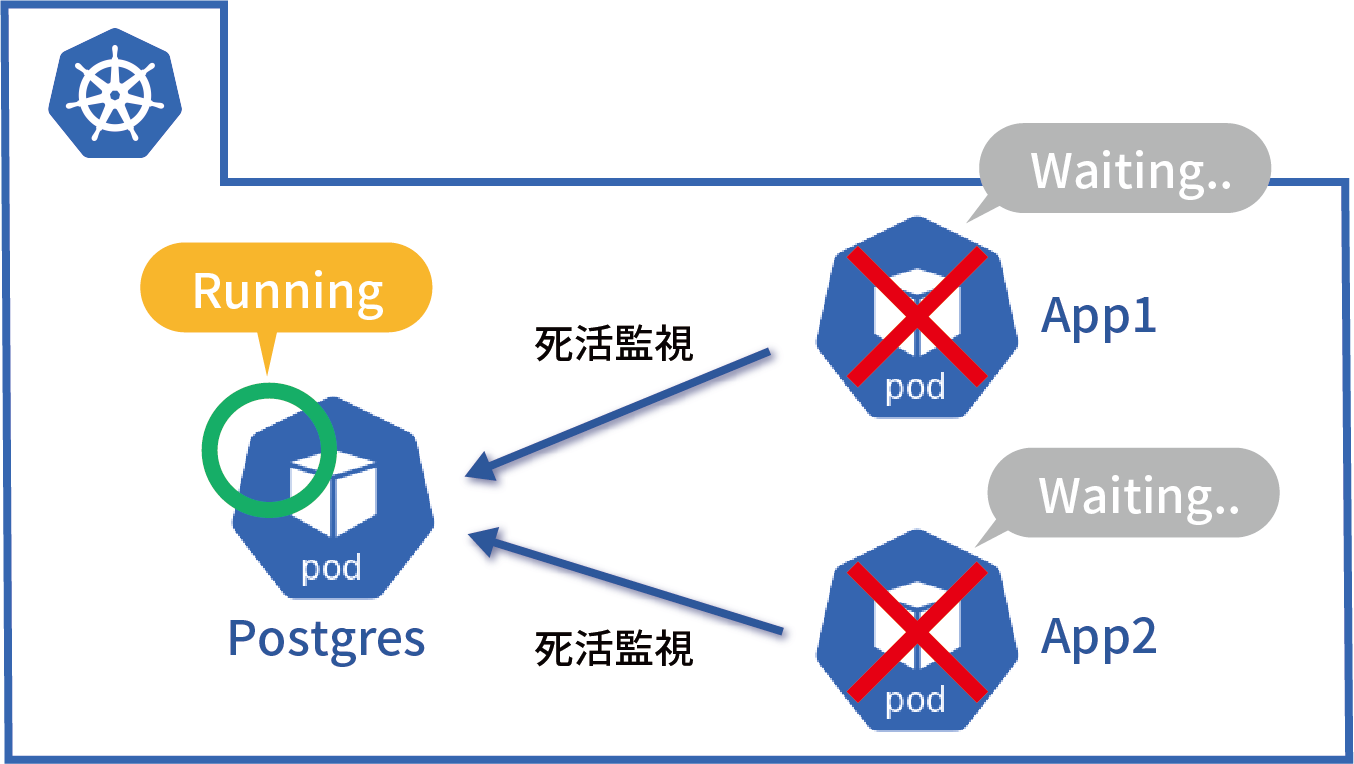
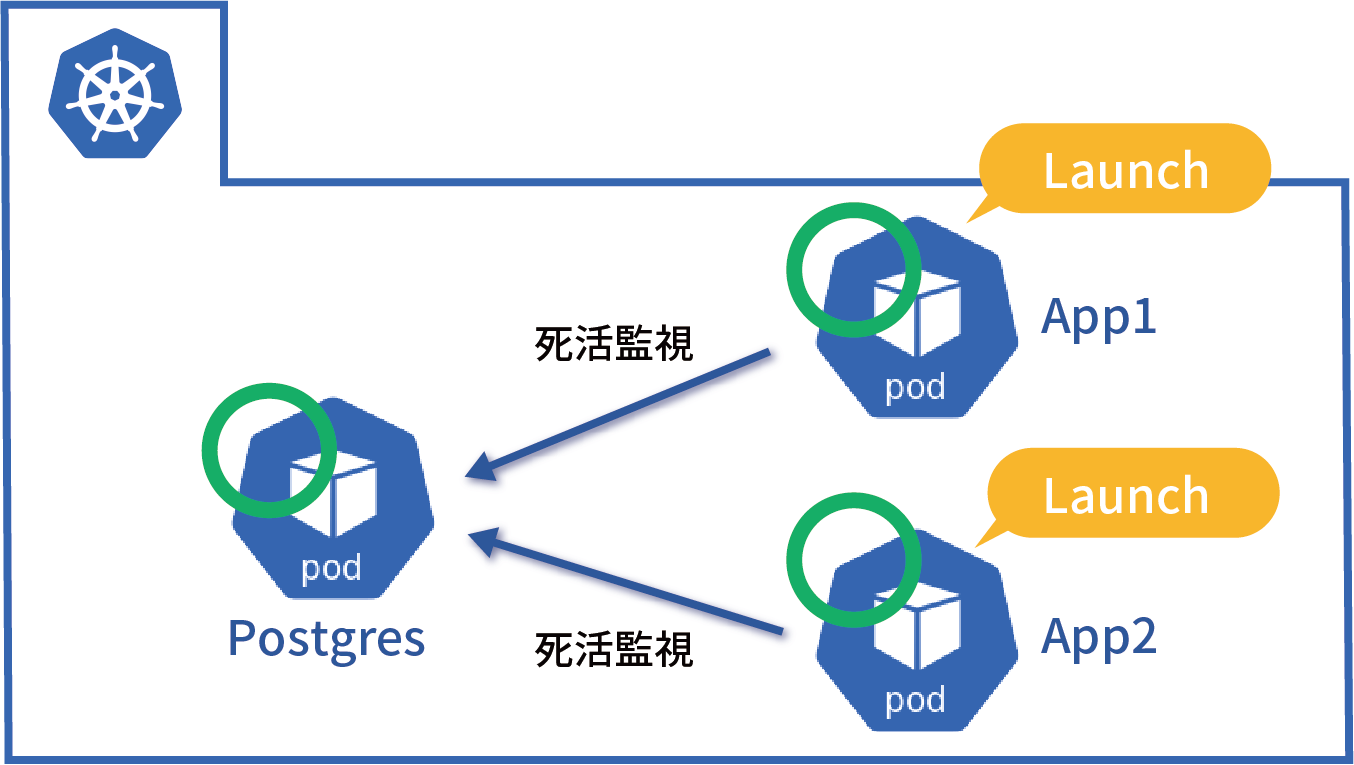
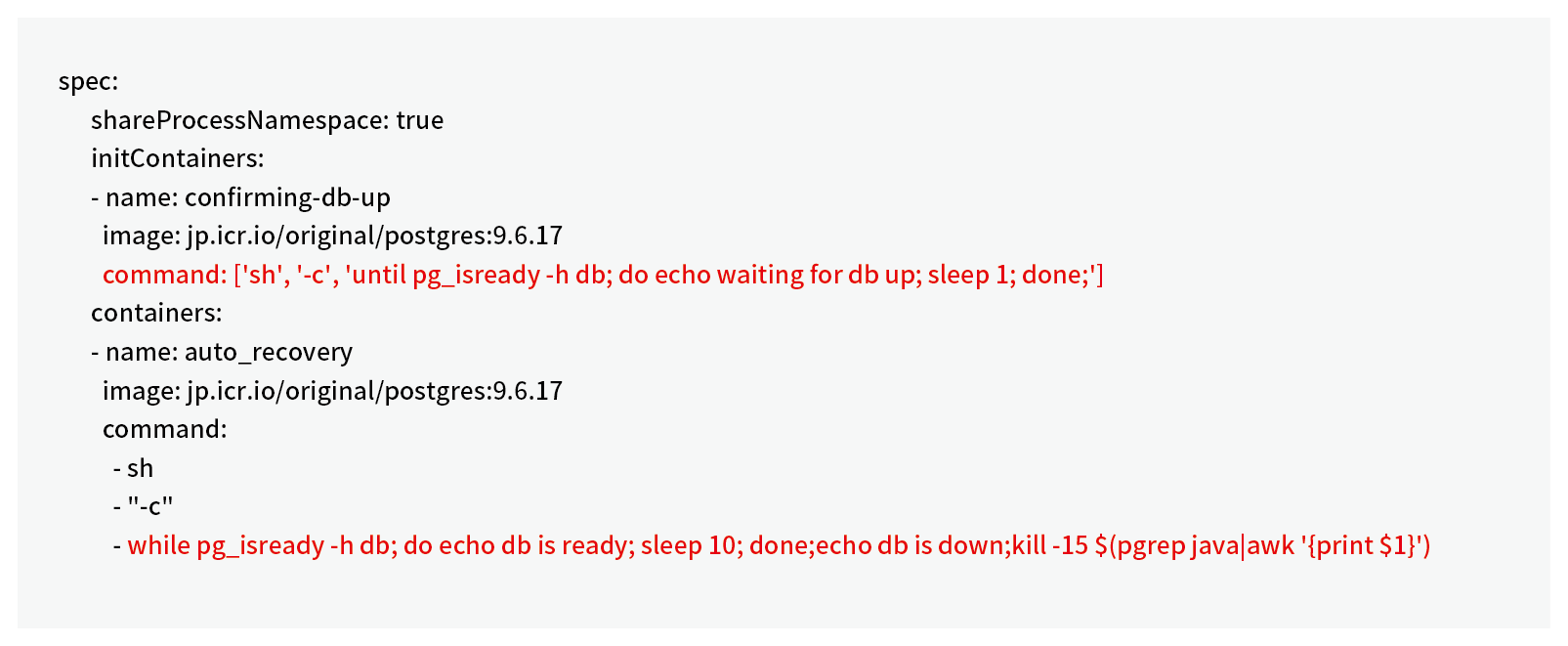
今回稼働環境として採用したIKSは、IBM Watsonやブロックチェーンなどと連携するアプリケーションを短時間で配信するためのマネージド・コンテナ・サービスです。AI DigはIBM Watsonを利用したアプリケーションであることから、運用面・コスト面も考慮し、IKSを採用しています。
ここでは、① IKS環境の準備/設計、② IKS環境の設定/アプリケーションのデプロイの2つに分けて解説します。
前回ご紹介したコラムで、AI Digのコンテナ化まで完了したので、今回は作成したコンテナイメージを動作させるIBM Cloudのマネージド型Kubernetesサービス「IBM Cloud Kubernetes Service(以下、IKS)」の設計・設定、そしてアプリケーションのデプロイについて紹介します。
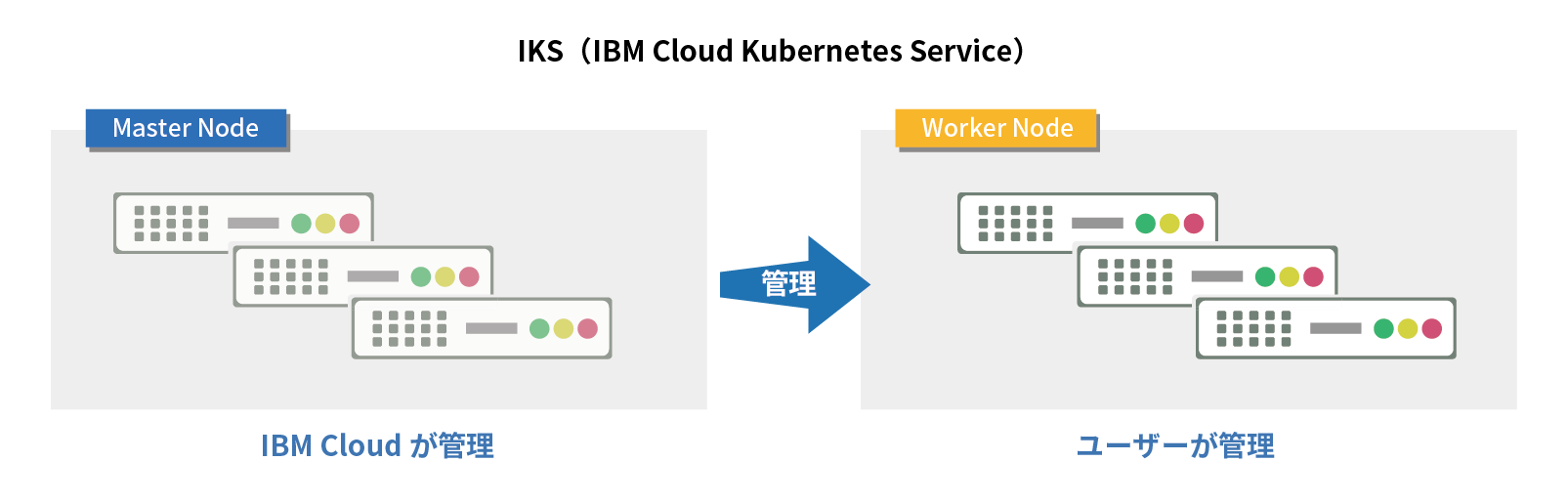
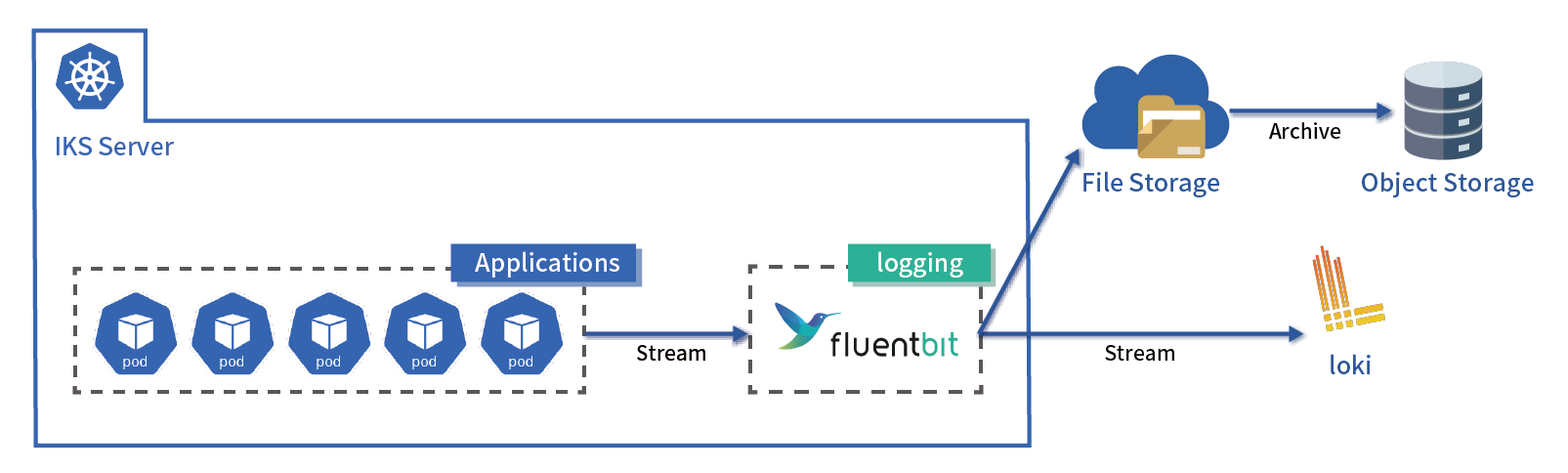
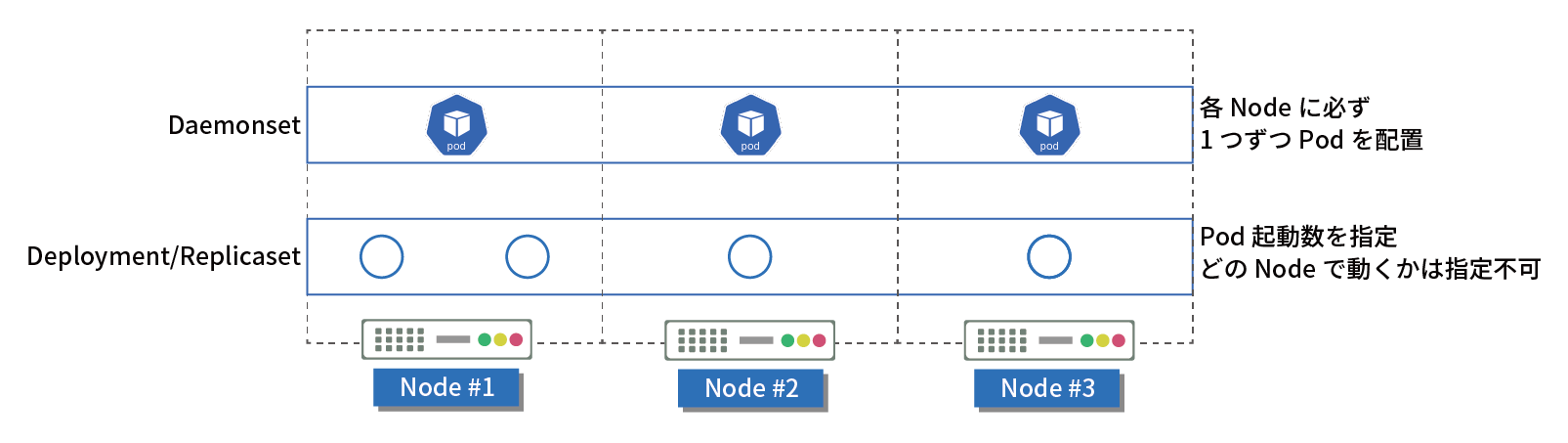
【手順】