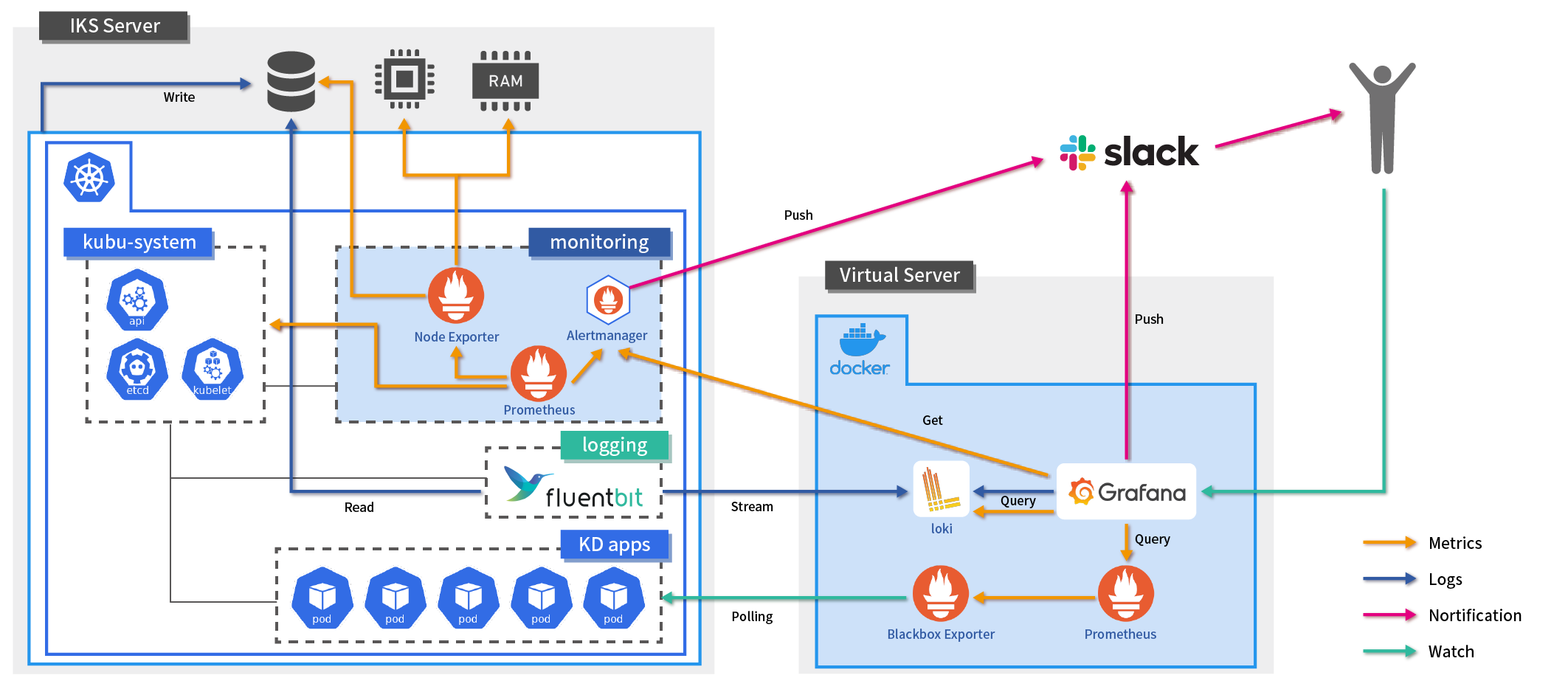
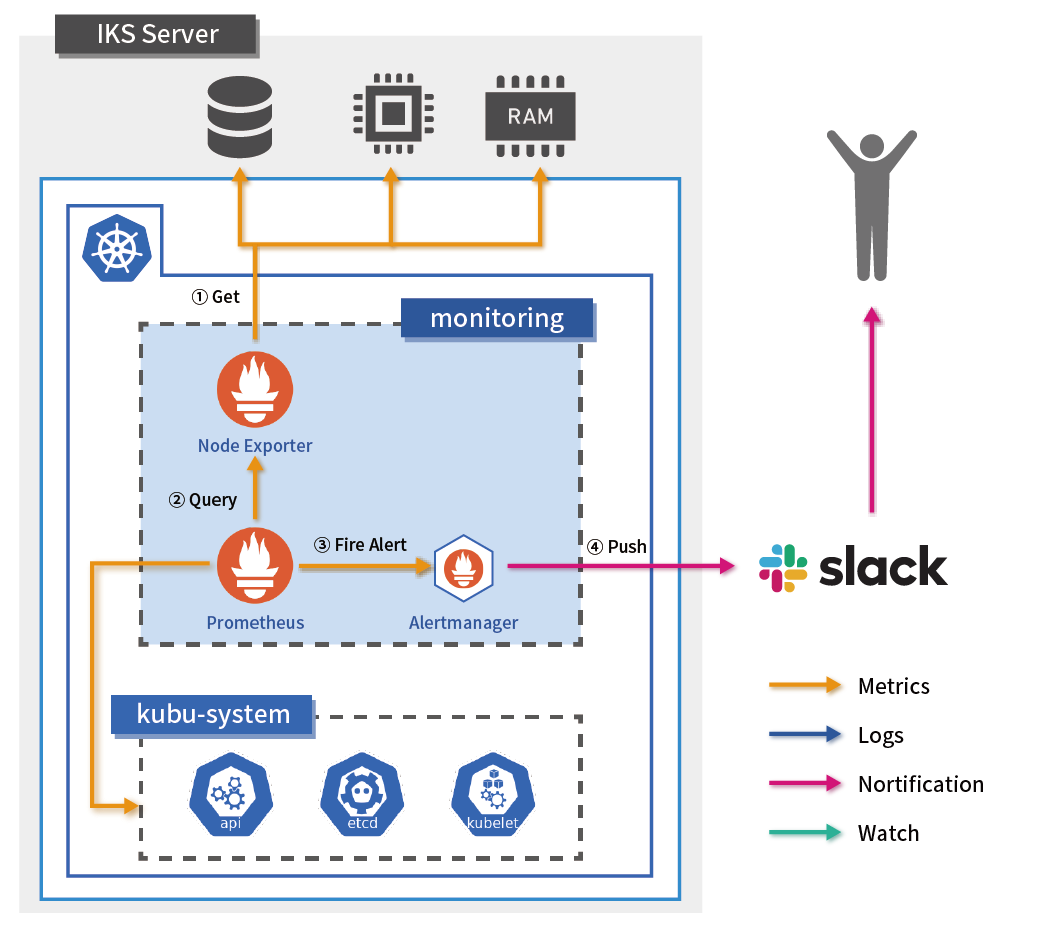
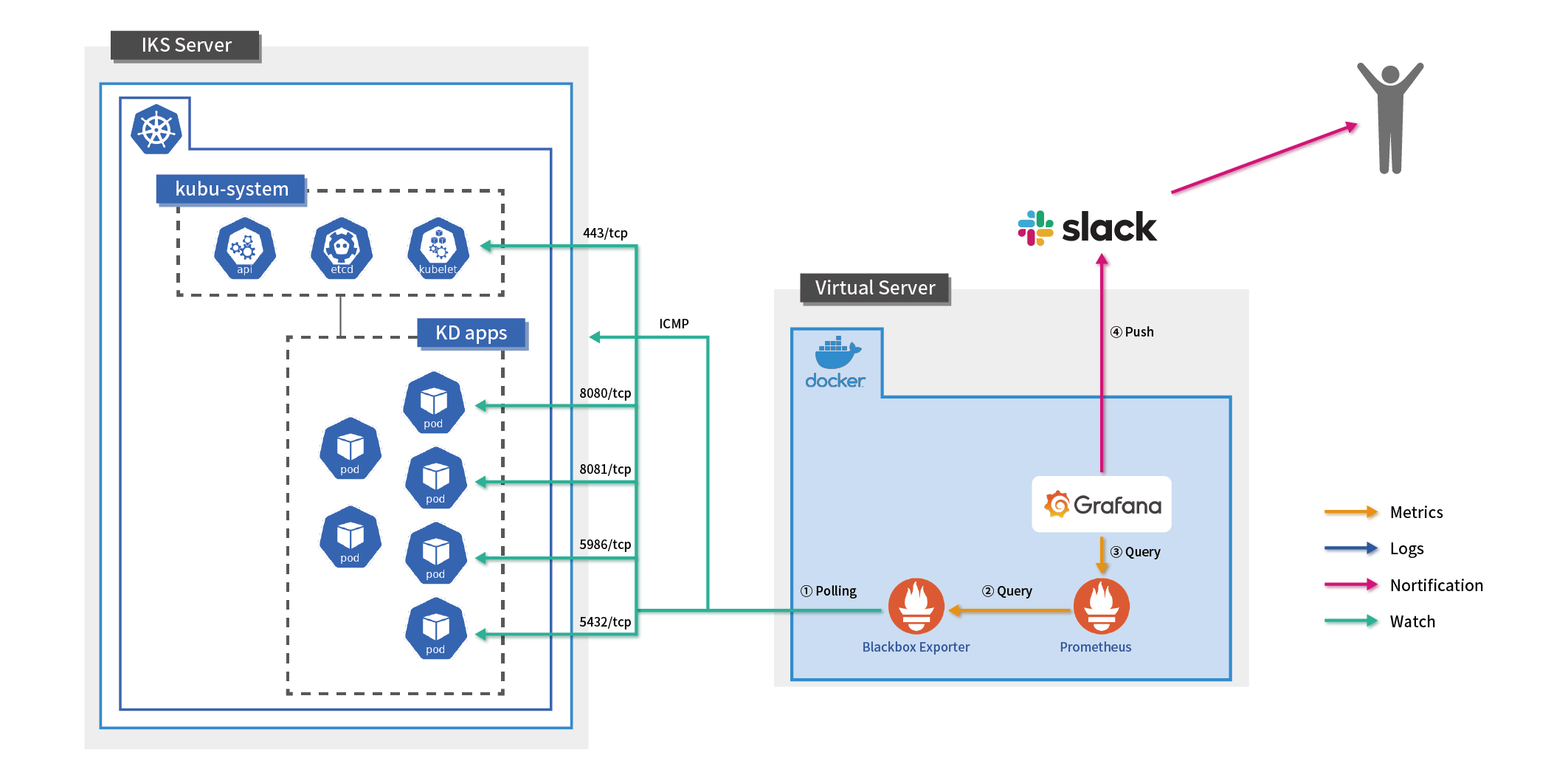
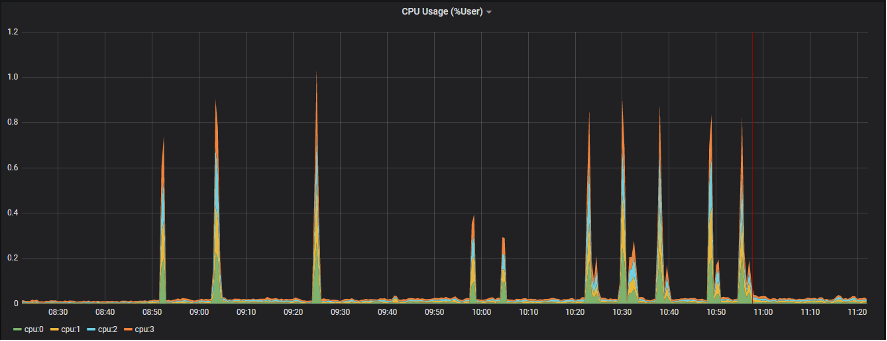
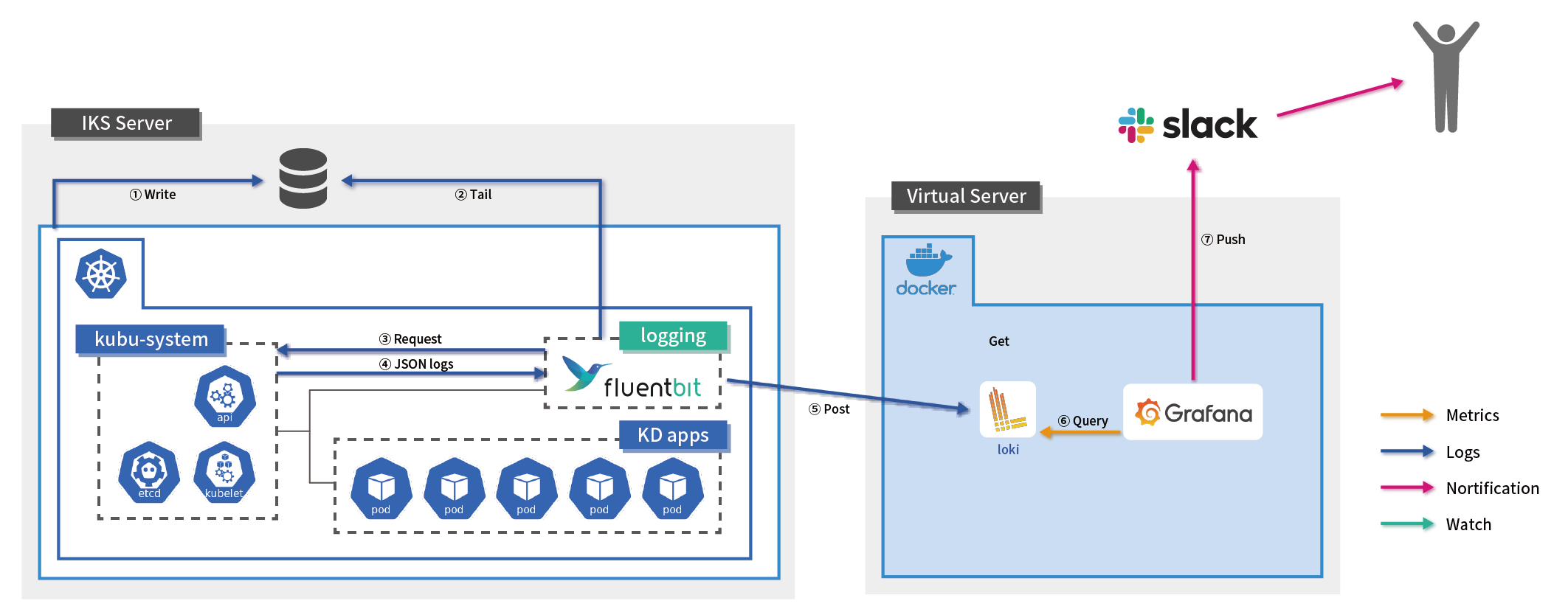
Kubernetes環境を監視する場合、コンテナアプリケーションがどのノードで稼働しているか外部から状況を把握することが難しく、また、コンテナのライフサイクルも短いため頻繁に稼働するノードが変更される可能性があるため、ノード単位での監視設定ができません。
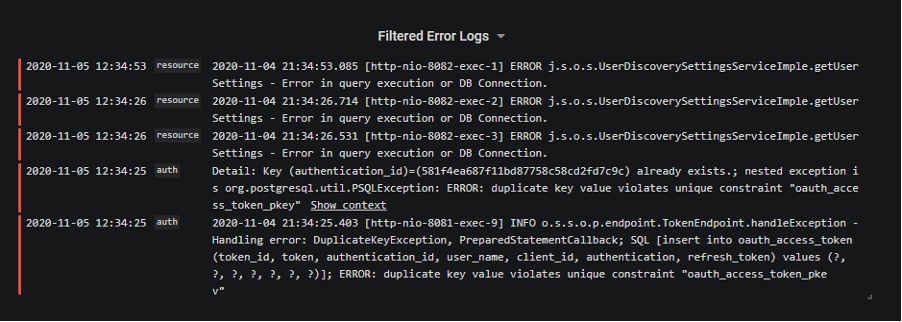
また、ログファイルがPod単位のため、同じアプリケーションでもPodがダウンすると別のログファイルとして扱われるなど、どのNamespaceのどのPodのログなのかを判別することが難しいという特徴もあります。
S&Iが従来から得意としているZabbixによるシステム監視は、ホスト(ノード)単位でAgentを導入し、決まった監視ルールの適用やIPアドレスベースでの死活監視など、静的監視がメインです。ノード単位での監視設定ができないKubernetes環境にはちょっと不向きです。
そこで今回は、コストの観点も考慮しながら、Kubernetesクラスタ内部からの監視と外部からの監視、そしてログ監視の機能の3つのポイントに重点を置いて構築しました。